
WOW…It works.

Seemingly, fear classification is not working.
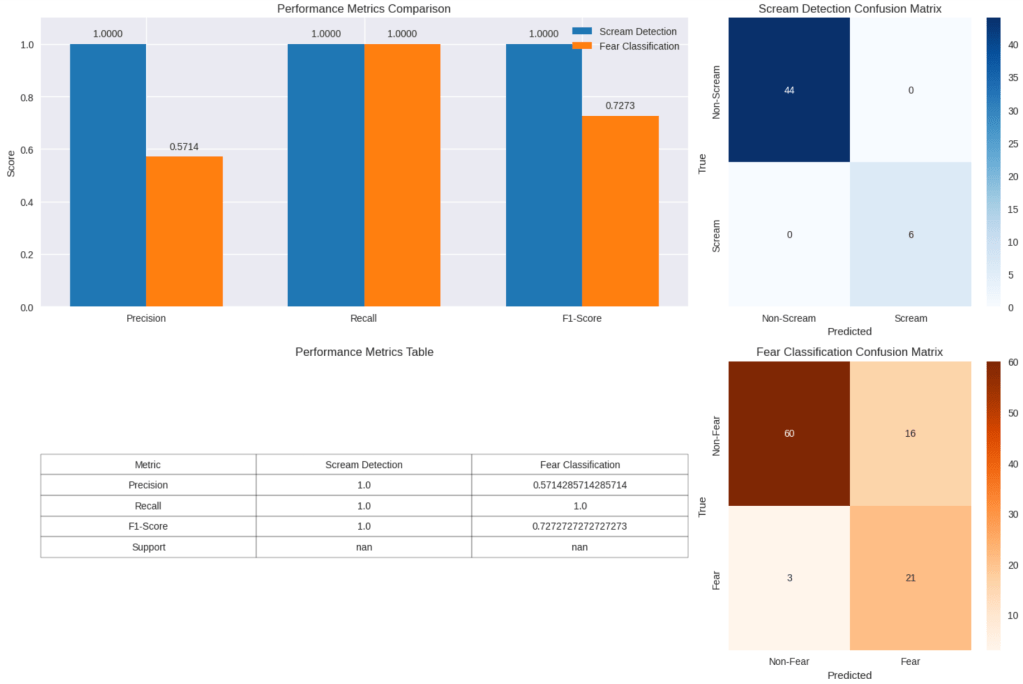
The Fear Metrics: (0.0, 0.0, 0.0, None) result indicates that fear classification completely failed. This is primarily because the test set (test_emotions = emotions[:50]) contains no fear samples (Test Emotions: [50]), meaning the CRNN model had no opportunity to predict fear (class 1). Although scream detection is successful (Scream Metrics: (1.0, 0.8776, 0.9348, None)), but fear classification is not working.
1.1. No Fear Samples in Test Set
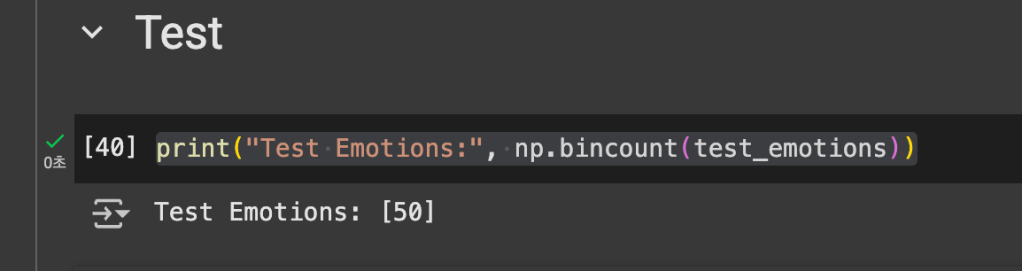
- Symptom: Test Emotions: [50] shows that the test set (test_emotions = emotions[:50]) contains only non-fear samples (class 0), with no fear samples (class 1).
- Impact: The CRNN model cannot predict fear, so precision_recall_fscore_support assigns 0.0 to Precision, Recall, and F1-Score for the fear class, as all predictions are non-fear.
- Cause: The test set was created by taking the first 50 samples (emotions[:50]) from dataset.h5. With ~192 fear samples in ~1,232 total clips (~15.6%), the first 50 samples are unlikely to include fear clips.
- Verification:
1.2. Class Imbalance
- Data Distribution: The full dataset has ~192 fear clips vs. ~1,040 non-fear clips (~1:5.42 ratio), a severe imbalance that biases CRNN training toward non-fear predictions.
- Class Weights: You used class_weights_fear = {0: 1.0, 1: 1040/192 ≈ 5.42}, but the small number of fear samples (~192) may not provide enough data for effective learning, even with weighting.
- Impact: The CRNN likely underfits the fear class, failing to learn its patterns, and defaults to predicting non-fear.
1.3. Insufficient CRNN Training
- Model Structure: Your CRNN (2D CNN + 1D CNN/GlobalMaxPooling1D) may not capture the temporal patterns critical for fear classification (e.g., emotional dynamics in screams). A model like LSTM could better handle these.
- Hyperparameters: The learning rate, number of epochs, or dropout rate may not be optimized for the complex task of fear classification with limited data.
- Overfitting/Underfitting: With few fear samples, the CRNN may overfit to non-fear data or underfit fear patterns.
1.4. Ensemble Weighting Issue
- Ensemble Logic: In fear_prob = (cnn_pred + crnn_pred) / 2, the CNN was trained for scream detection, not fear classification, so its predictions may dilute the CRNN’s fear-specific signals.
- Impact: Even if the CRNN learned some fear patterns, the CNN’s non-fear-biased predictions could push fear_prob below the 0.5 threshold, resulting in all non-fear predictions.
1.5. TensorFlow Retracing Warnings
- Warning: WARNING:tensorflow:6 out of the last 6 calls to <function …> triggered tf.function retracing during CRNN prediction.
- Cause:
- Inconsistent Input Shapes: The test_mel input to crnn_model.predict may have varying shapes across batches.
- Non-Tensor Inputs: Passing NumPy arrays instead of tensors can trigger retracing.
- Dynamic @tf.function Calls: Calling predict in a loop or with dynamic operations causes retracing.
- Impact: Retracing slows prediction (~1s for 2/2 steps), which is critical for real-time inference in your project, though it doesn’t affect correctness.
In real world, we detect scream first, then find whether it comes out from fear.
So, I have changed the strategy from detecting scream and emotions simultaneously, find whether it comes out from scream then, find whether it comes out from fear or not.
It is worthy for three reasons. First, Clear Task Separation: First identifying screams reduces the complexity of the emotion classification step, as the model only processes confirmed screams rather than all sounds. Second, Real-World Efficiency: Screams are rare, so filtering out non-screams early saves computational resources and reduces false positives in emotion analysis. Third, Data Imbalance Handling: By focusing on scream detection first, you can handle the imbalanced nature of screams vs. non-screams (e.g., 1:20 ratio, as discussed) before tackling emotion-specific challenges.
Stage 1: Scream Detection
- Model: Implemented a binary classifier to determine if a sound is a scream or not. Current metrics (precision 1.0, recall ~0.878, F1 ~0.935 ) suggest model (likely YAMNet or CRNN) is already strong here.
- Dataset: Continue using FSD50K, ESC-50, or RAVDESS, but ensure the dataset includes diverse non-scream sounds (e.g., laughter, shouting, ambient noise) to mimic real-world conditions.
- Features: Extract audio features like MFCCs, spectrograms, or embeddings from YAMNet. Since YAMNet is pretrained on AudioSet, it’s a solid choice for robust scream detection.
Stage 2: Emotion Classification (Fear Detection)
- Model: Once a scream is detected, pass it to a second model to classify the emotion (e.g., fear, anger, joy). A CNN or CRNN trained on emotional audio features works well here.
- Dataset: Use RAVDESS with labeled emotional screams.
- Limitation : Since fear samples may be limited, consider:
- Data Augmentation: Generate synthetic fear screams using pitch/time stretching or GAN-based audio synthesis.
- Transfer Learning: Fine-tune a pre-trained model (e.g., YAMNet or VGGish) on fear-specific screams.
- Features: Focus on temporal and spectral features (e.g., pitch contour, energy dynamics) that differentiate fear-based screams from others. Fear screams often have higher pitch and irregular patterns.
- It is one the most important steps that I have worked on.
- Feature extraction is indeed critical for scream detection and emotion classification, as it directly impacts your model’s ability to distinguish screams (and fear-based screams specifically) from other sounds. As far as I am concerned, the right features should capture the unique acoustic properties of screams and the emotional nuances of fear. I outline the most important types of audio features for this task, focusing on their relevance to scream detection and fear classification, and draw insights from similar efforts in audio classification (e.g., speech emotion recognition, environmental sound classification).
- Insights from similar efforts :
- Speech Emotion Recognition (SER):
- Datasets like RAVDESS and IEMOCAP use MFCCs, pitch, and energy features to classify emotions (e.g., fear, anger, sadness). Studies show that combining low-level features (MFCCs) with high-level embeddings (e.g., VGGish) improves accuracy for high-arousal emotions like fear.
- Example: A 2020 study on RAVDESS achieved ~80% accuracy for fear detection using MFCCs + pitch + CNN.
- Environmental Sound Classification:
- Tasks like DCASE and ESC-50 use log-Mel spectrograms and YAMNet embeddings to detect events like screams or alarms. These features are robust to background noise, which is critical for your daily-life application.
- Example: YAMNet-based models on FSD50K achieve high F1-scores (~0.9) for scream detection.
- Scream Detection:
- Research on scream detection in surveillance systems (e.g., AudioSet-based studies) emphasizes high-frequency energy and temporal irregularity (ZCR, spectral flux). These align with fear scream characteristics
- Speech Emotion Recognition (SER):
- Training Tips:
- Use weighted loss to prioritize fear detection, as it’s your primary target.
- Evaluate with a balanced test set containing fear and non-fear screams to ensure robust emotion classification.
import librosa
import numpy as np
import h5py
import pandas as pd
def preprocess_and_save(metadata_path, output_h5, target_sr=16000):
metadata = pd.read_csv(metadata_path)
N = len(metadata)
with h5py.File(output_h5, 'w') as f:
# Datasets for features
mel_specs = f.create_dataset('mel_specs', shape=(N, 128, 128), dtype='float32')
waveforms = f.create_dataset('waveforms', shape=(N, target_sr * 3), dtype='float32')
mfccs = f.create_dataset('mfccs', shape=(N, 13), dtype='float32') # 13 MFCCs
mfccs_delta = f.create_dataset('mfccs_delta', shape=(N, 13), dtype='float32') # MFCC deltas
pitch = f.create_dataset('pitch', shape=(N, 2), dtype='float32') # Mean and variance
rms = f.create_dataset('rms', shape=(N, 2), dtype='float32') # Mean and variance
labels = f.create_dataset('labels', shape=(N,), dtype='int32')
emotions = f.create_dataset('emotions', shape=(N,), dtype='int32')
filenames = f.create_dataset('filenames', shape=(N,), dtype=h5py.string_dtype(encoding='utf-8'))
sources = f.create_dataset('sources', shape=(N,), dtype=h5py.string_dtype(encoding='utf-8'))
for i, row in metadata.iterrows():
try:
# Load and preprocess audio (3 seconds at 16kHz)
audio, sr = librosa.load(row['filename'], sr=target_sr)
audio = audio[:target_sr * 3] if len(audio) > target_sr * 3 else np.pad(audio, (0, target_sr * 3 - len(audio)))
# Log-Mel Spectrogram
mel_spec = librosa.feature.melspectrogram(y=audio, sr=sr, n_mels=128, hop_length=int(target_sr * 3 / 128))
mel_spec = librosa.power_to_db(mel_spec, ref=np.max)
# MFCCs and deltas
mfcc = librosa.feature.mfcc(y=audio, sr=sr, n_mfcc=13)
mfcc_delta = librosa.feature.delta(mfcc)
# Pitch (F0)
pitches, magnitudes = librosa.piptrack(y=audio, sr=sr)
valid_pitches = pitches[magnitudes > 0]
pitch_mean = np.mean(valid_pitches) if valid_pitches.size > 0 else 0
pitch_var = np.var(valid_pitches) if valid_pitches.size > 0 else 0
# Energy (RMS)
rms_values = librosa.feature.rms(y=audio)
rms_mean = np.mean(rms_values)
rms_var = np.var(rms_values)
# Save features
mel_specs[i] = mel_spec[:, :128]
waveforms[i] = audio
mfccs[i] = np.mean(mfcc, axis=1) # Average over time
mfccs_delta[i] = np.mean(mfcc_delta, axis=1)
pitch[i] = [pitch_mean, pitch_var]
rms[i] = [rms_mean, rms_var]
labels[i] = row['label']
emotions[i] = row['emotion']
filenames[i] = row['filename']
sources[i] = row['source']
except Exception as e:
print(f"Error processing {row['filename']}: {e}")
continue
print(f"Saved to {output_h5}")
# Example usage (assuming metadata CSV exists)
base_dir = './' # Adjust to your directory
metadata_path = base_dir + 'unified_metadata.csv'
output_h5 = base_dir + 'dataset.h5'
preprocess_and_save(metadata_path, output_h5)
- Also changed models
However, for your specific task—detecting fear-based screams in daily life—there are opportunities to optimize the architectures to better capture the temporal and spectral nuances of fear (e.g., high pitch, irregular energy bursts). Below, I’ll evaluate the effectiveness of both models, suggest improvements to their layers, and tailor them to your goal of fear classification within a two-stage pipeline (scream detection → fear classification). Since fear is a high-arousal emotion with distinct acoustic patterns, the models need to effectively process both spatial (spectral) and temporal features.
Evaluation of Your Current Models
CNN Model
- Architecture:
- Two Conv2D layers (32 and 64 filters) with MaxPooling2D to extract spatial features from log-Mel spectrograms.
- Flattening followed by a dense layer (128 units) and a sigmoid output for binary classification (fear vs. non-fear).
- Strengths:
- Simple and lightweight, suitable for initial experiments.
- Log-Mel spectrograms (128x128x1) are well-suited for CNNs, capturing frequency-time patterns critical for fear (e.g., energy bursts).
- Binary classification with sigmoid and binary_crossentropy aligns with fear detection.
- Weaknesses:
- Limited Depth: Only two convolutional layers may not capture complex patterns in fear screams, which have subtle spectral variations compared to anger or joy.
- No Regularization: Lacks dropout or batch normalization, risking overfitting, especially with limited fear samples (e.g., from RAVDESS)
- No Temporal Modeling: Fear screams have dynamic temporal patterns (e.g., pitch fluctuations), which a pure CNN may not fully exploit.
- Feature Integration: Doesn’t incorporate additional features like MFCCs, pitch, or RMS from your preprocessing, limiting its ability to focus on fear-specific cues.
CRNN Model
- Architecture:
- Two Conv2D layers (32 filters each) with MaxPooling2D, followed by reshaping to feed into a Conv1D layer for temporal modeling.
- GlobalMaxPooling1D to reduce dimensionality, followed by dense layers and a sigmoid output.
- Strengths:
- Combines spatial (Conv2D) and temporal (Conv1D) processing, better suited for fear’s dynamic patterns (e.g., rapid energy changes).
- GlobalMaxPooling1D reduces parameters, making it computationally efficient.
- Same input (log-Mel spectrograms) leverages your preprocessing pipeline.
- Weaknesses:
- Shallow CNN Component: Similar to the CNN model, two Conv2D layers may not extract deep spectral features.
- Limited Temporal Modeling: A single Conv1D layer may not capture long-term dependencies in fear screams (e.g., pitch contour changes over time). An RNN (e.g., LSTM/GRU) would be more effective.
- No Feature Fusion: Ignores MFCCs, pitch, and RMS features, which are critical for distinguishing fear from other emotions.
- No Regularization: Like the CNN, lacks dropout or batch normalization, increasing overfitting risk.
Are These Models Effective for Fear Detection?
- Current Effectiveness: Both models are decent baselines for binary fear classification using log-Mel spectrograms, but they’re likely underperforming for fear detection due to:
- Shallow architectures that may miss complex fear-specific patterns.
- Lack of regularization, which is critical given the scarcity of fear samples.
- No integration of fear-specific features (pitch, MFCCs, RMS) from your preprocessing.
- Limited temporal modeling in the CNN and insufficient RNN depth in the CRNN.
- Real-World Challenges: In daily life, fear screams occur in noisy environments (e.g., cafes, streets). Without robust feature extraction and regularization, these models may struggle with noise and generalize poorly.
Suggested Improvements
To make the models more effective for fear detection, I’ll propose modifications to both architectures, focusing on:
- Deeper Feature Extraction: Add layers to capture complex spectral and temporal patterns.
- Feature Fusion: Incorporate MFCCs, pitch, and RMS from your preprocessing.
- Regularization: Add dropout and batch normalization to prevent overfitting.
- Temporal Modeling: Enhance the CRNN with LSTM/GRU for long-term dependencies.
- Robustness: Account for real-world noise and data scarcity.
Improved CNN Model
The CNN should focus on extracting robust spectral features from log-Mel spectrograms and integrate additional features (MFCCs, pitch, RMS) for fear classification.
import tensorflow as tf
def create_cnn_model_to_find_fear():
# Input for log-Mel spectrograms
mel_input = tf.keras.Input(shape=(128, 128, 1), name='mel_input')
x = tf.keras.layers.Conv2D(32, (3, 3), activation='relu', padding='same')(mel_input)
x = tf.keras.layers.BatchNormalization()(x)
x = tf.keras.layers.MaxPooling2D((2, 2))(x)
x = tf.keras.layers.Conv2D(64, (3, 3), activation='relu', padding='same')(x)
x = tf.keras.layers.BatchNormalization()(x)
x = tf.keras.layers.MaxPooling2D((2, 2))(x)
x = tf.keras.layers.Conv2D(128, (3, 3), activation='relu', padding='same')(x)
x = tf.keras.layers.BatchNormalization()(x)
x = tf.keras.layers.MaxPooling2D((2, 2))(x)
x = tf.keras.layers.Flatten()(x)
# Input for additional features (13 MFCCs + 13 deltas + 2 pitch + 2 RMS = 30)
feat_input = tf.keras.Input(shape=(30,), name='feat_input')
y = tf.keras.layers.Dense(64, activation='relu')(feat_input)
y = tf.keras.layers.BatchNormalization()(y)
# Combine features
combined = tf.keras.layers.Concatenate()([x, y])
combined = tf.keras.layers.Dense(128, activation='relu')(combined)
combined = tf.keras.layers.Dropout(0.5)(combined)
output = tf.keras.layers.Dense(1, activation='sigmoid')(combined)
model = tf.keras.Model(inputs=[mel_input, feat_input], outputs=output)
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy', tf.keras.metrics.Precision(), tf.keras.metrics.Recall()])
return model
cnn_model_fear = create_cnn_model_to_find_fear()
cnn_model_fear.summary()

Leave a comment